

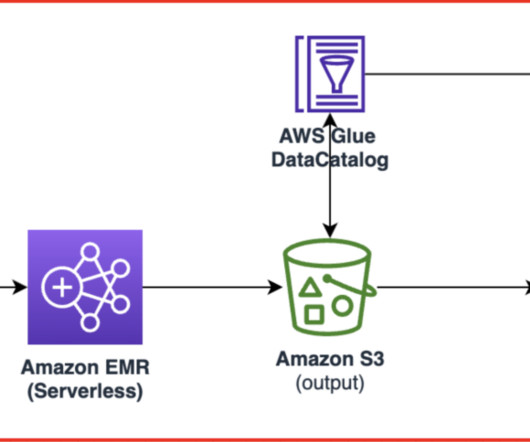
Orchestrate Amazon EMR Serverless Spark jobs with Amazon MWAA, and data validation using Amazon Athena
AWS Big Data
DECEMBER 12, 2023
Many data engineers today use Apache Airflow to build, schedule, and monitor their data pipelines. Amazon Managed Workflows for Apache Airflow (Amazon MWAA) can help simplify the process of building, running, and managing data pipelines. You can use standard SQL to interact with data.





















Let's personalize your content