

How gaming companies can use Amazon Redshift Serverless to build scalable analytical applications faster and easier
AWS Big Data
MARCH 7, 2023
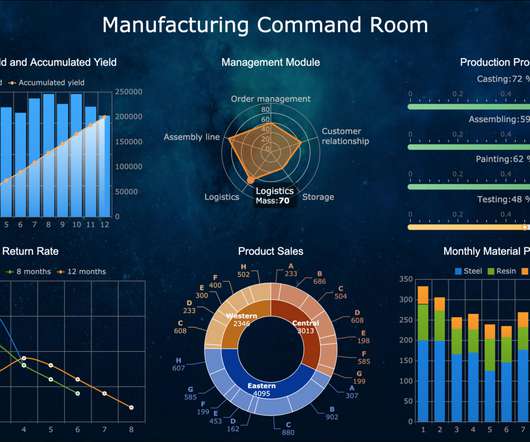
Sources Data can be loaded from multiple sources, such as systems of record, data generated from applications, operational data stores, enterprise-wide reference data and metadata, data from vendors and partners, machine-generated data, social sources, and web sources.

















Let's personalize your content