

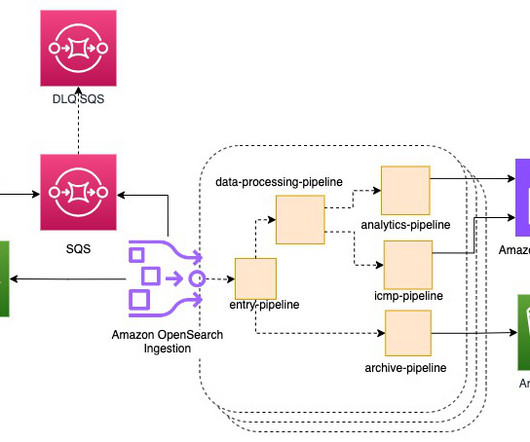
Enable cost-efficient operational analytics with Amazon OpenSearch Ingestion
AWS Big Data
OCTOBER 25, 2023
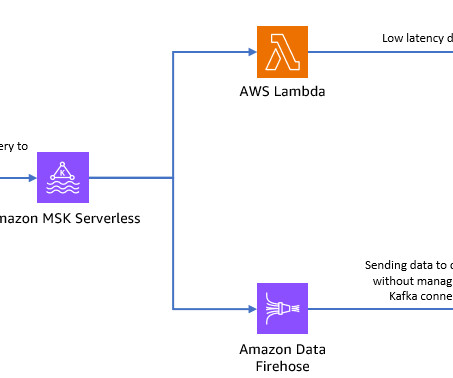
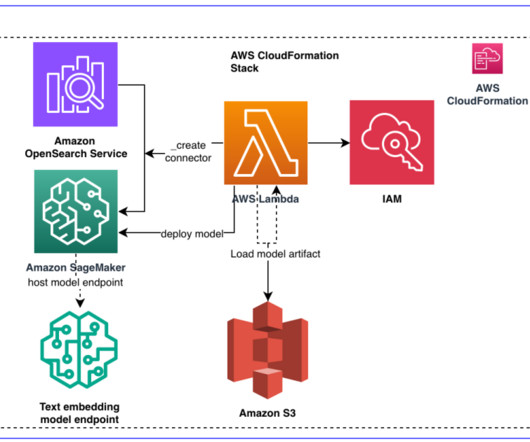
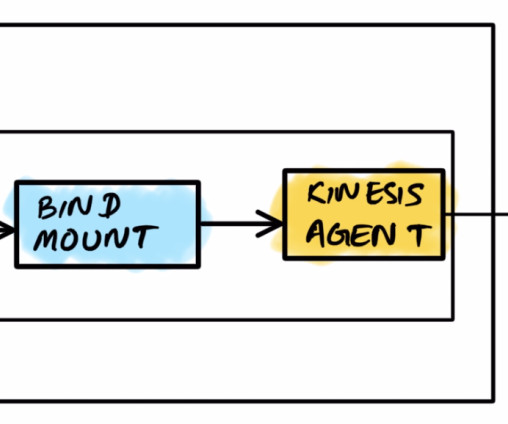
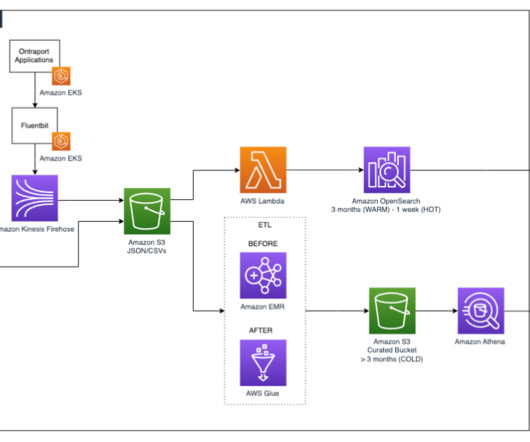
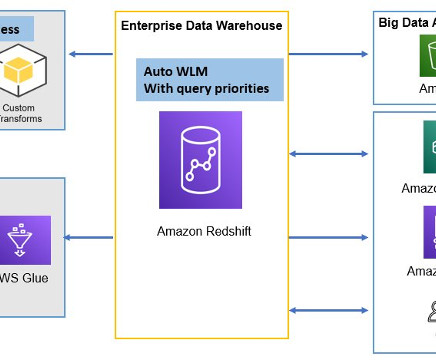
As the scale and complexity of microservices and distributed applications continues to expand, customers are seeking guidance for building cost-efficient infrastructure supporting operational analytics use cases. Operational analytics is a popular use case with Amazon OpenSearch Service.






































Let's personalize your content