


Measure performance of AWS Glue Data Quality for ETL pipelines
AWS Big Data
MARCH 12, 2024
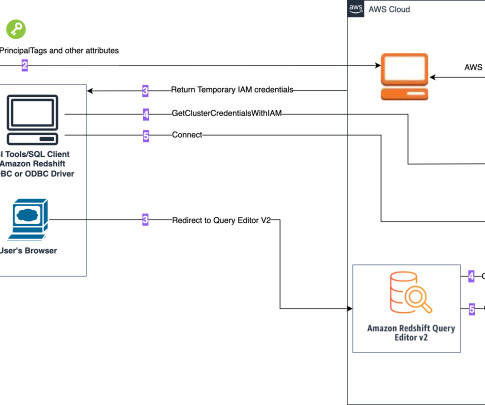
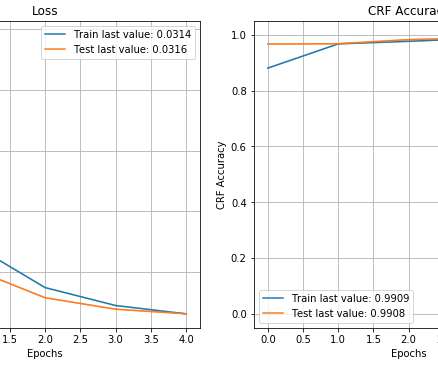
If you opt to run the generator script, you need to install the Pandas and Mimesis packages in your Python environment: pip install pandas mimesis The dataset schema is a combination of numerical, categorical, and string variables in order to have enough attributes to use a combination of built-in AWS Glue Data Quality rule types.

















Let's personalize your content