


Spark on AWS Lambda: An Apache Spark runtime for AWS Lambda
AWS Big Data
OCTOBER 30, 2023
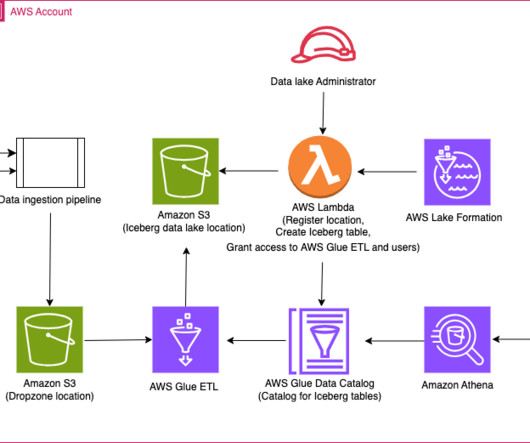
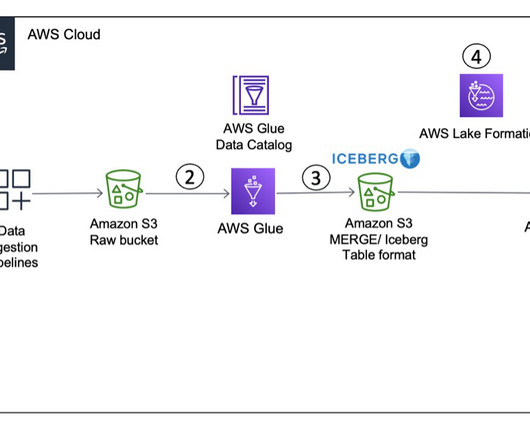
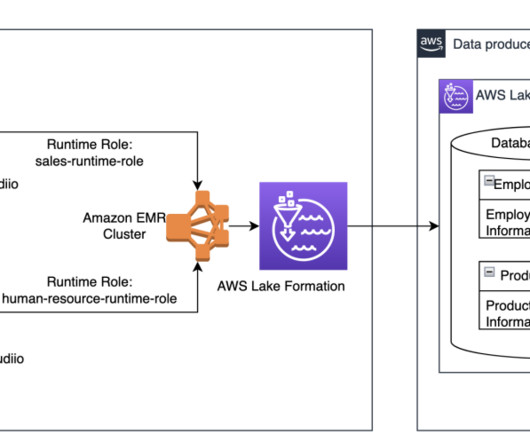
Spark on AWS Lambda (SoAL) is a framework that runs Apache Spark workloads on AWS Lambda. SoAL provides a framework that enables you to run data-processing engines like Apache Spark and take advantage of the benefits of serverless architecture, like auto scaling and compute for analytics workloads.













































Let's personalize your content