


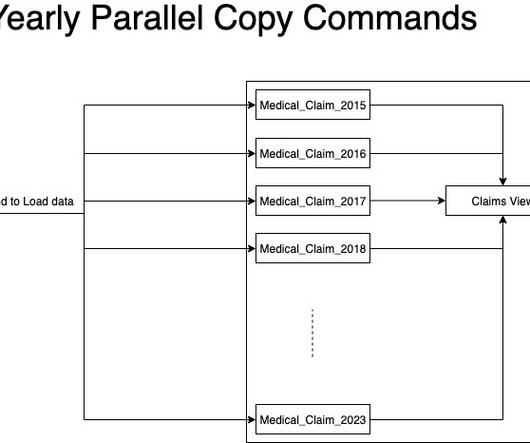
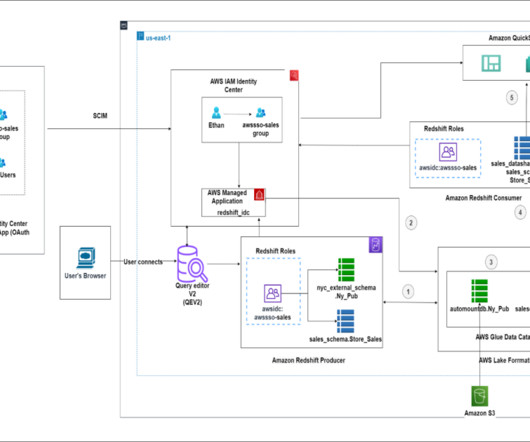
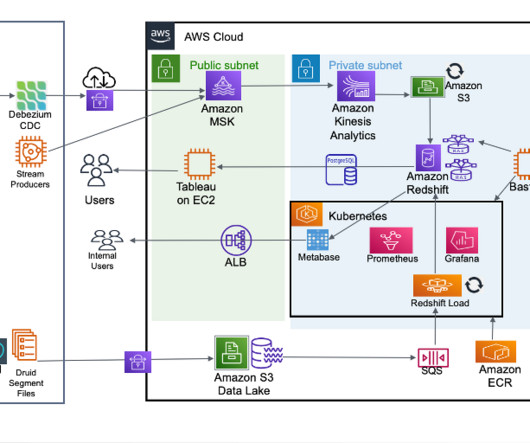
Data Lakes Meet Data Warehouses
David Menninger's Analyst Perspectives
MAY 7, 2020
In this analyst perspective, Dave Menninger takes a look at data lakes. He explains the term “data lake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and data lakes and share some of Ventana Research’s findings on the subject.














































Let's personalize your content