
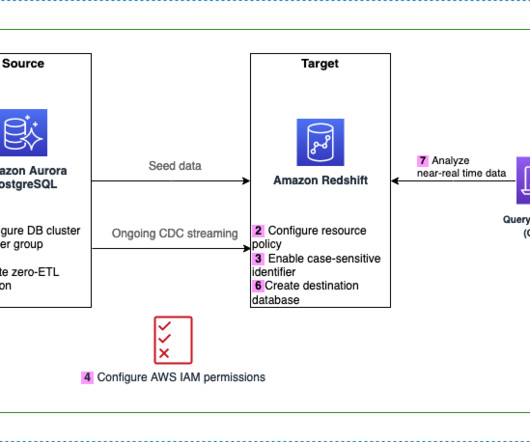
Achieve near real time operational analytics using Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift
AWS Big Data
APRIL 10, 2024
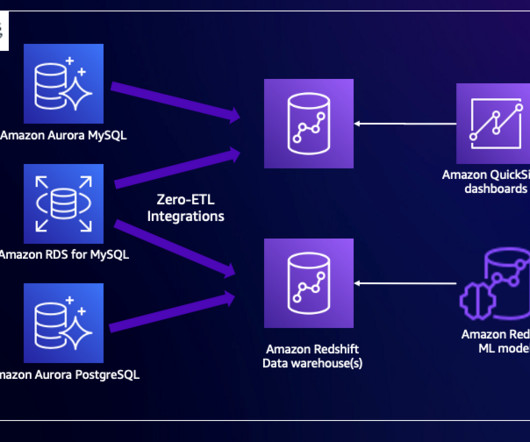
and zero-ETL support) as the source, and a Redshift data warehouse as the target. The integration replicates data from the source database into the target data warehouse. Additionally, you can choose the capacity, to limit the compute resources of the data warehouse. For this post, set this to 8 RPUs.



































Let's personalize your content