

Defining Simplicity for Enterprise Software as “a 10 Year Old Can Demo it”
Cloudera
NOVEMBER 12, 2021
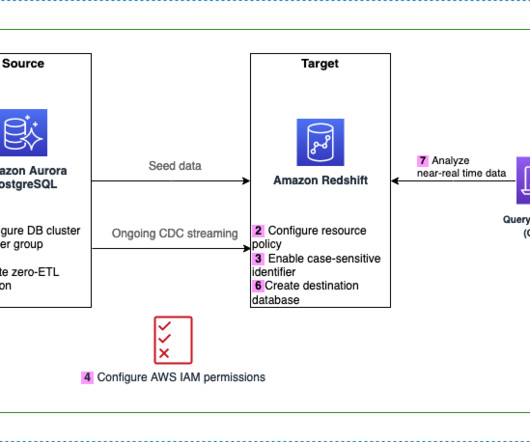
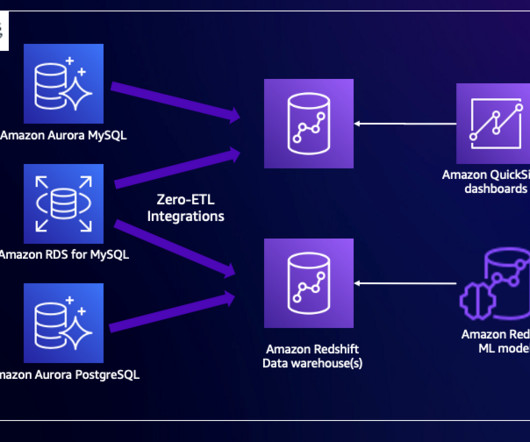
During the development of Operational Database and Replication Manager, I kept telling folks across the team it has to be “so simple that a 10 year old can demo it”. so simple that a 10 year old can demo it”. Watch this: Enterprise Software that is so easy a 10 year old can demo it. Create a snapshot .












































Let's personalize your content