
Amazon OpenSearch Service Under the Hood : OpenSearch Optimized Instances(OR1)
AWS Big Data
APRIL 17, 2024
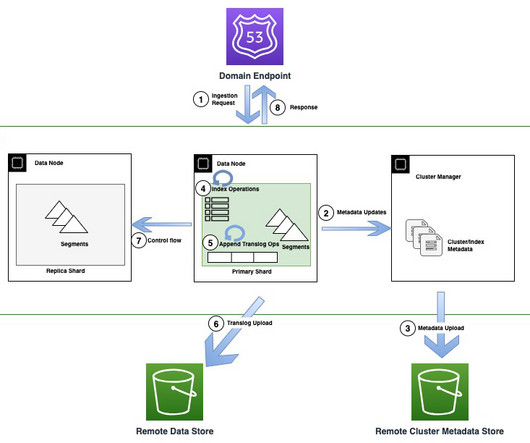
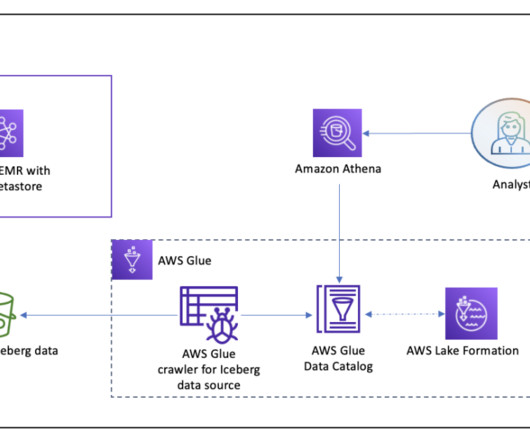
Designing for high throughput with 11 9s of durability OpenSearch Service manages tens of thousands of OpenSearch clusters. The following diagram illustrates the recovery flow in OR1 instances OR1 instances persist not only the data, but the cluster metadata like index mappings, templates, and settings in Amazon S3.













































Let's personalize your content