Top 3 Trends in Data Infrastructure for 2021

Data engineering continues to be a top priority for enterprises, and in 2021, there will be exciting developments in the data infrastructure space. In a recent webinar, Maksim Percherskiy, Data Engineer at The World Bank and former Chief Data Officer of the City of San Diego, highlighted three trends to watch out for in particular: data orchestration platforms, data discovery engines, and data lakehouses.
Data orchestration platforms
Although orchestration platforms have been around for many years to manage computer systems and software, data orchestration is a relatively new concept that abstracts data access across storage systems, virtualizes data, and presents data to data-driven applications. Data orchestration platforms help companies become more data-driven by combining siloed data from multiple data storage locations and making them usable. Examples include Apache Airflow, Prefect, Luigi, and Stitch, which are compatible with modern software approaches like version control, DevOps, and continuous integration.
DataCamp’s course Introduction to Airflow in Python is a great place to start to learn how to implement and schedule ETL and data engineering workflows in an easy and repeatable way.
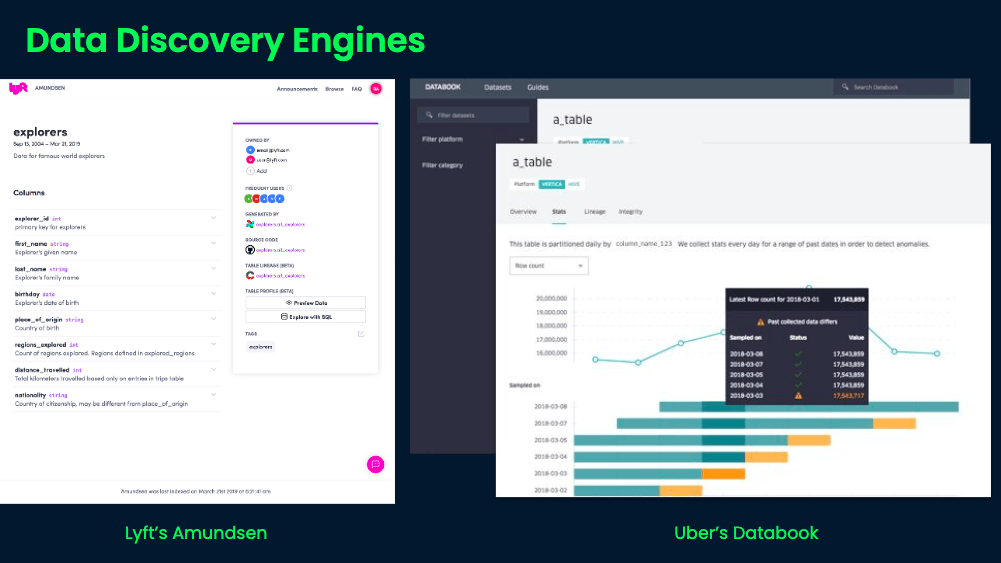
Data discovery engines
It makes sense that as data increases, companies will invest more time in enabling their teams to find the data they need, document it, and reduce rework. Data discovery engines like Lyft’s Amundsen and Uber’s Databook aim to improve the productivity of data users by providing a search interface for data. These tools rely on metadata, which support productivity and compliance by allowing data infrastructure to scale as companies grow. The goal of data discovery is to make data more FAIR: findable, accessible, interoperable, and reusable.
Data lakehouse
There are different use cases for data lakes versus data warehouses. Each is designed for different purposes and for different end users. For example, data warehouses are typically used by analysts for the purpose of collecting business intelligence—they contain flat files that have been explicitly processed for their work. On the other hand, data lakes are set up and maintained by data engineers who integrate them into data pipelines. Data scientists work more closely with data lakes as they contain data of a wider and more current scope.
Data lakehouses are exactly what they sound like: a combination of data lakes and data warehouses. Platforms like Snowflake and Databrick's Delta Lake have created solutions to provide a single source of truth for data that combines the benefits of data lakes and data warehouses. Data lakehouses implement data warehouses’ data structures and management features for data lakes, which are typically more cost-effective for data storage. At the same time, they retain the schema and versioning of the data. With data lakehouses, data scientists will be able to conduct both machine learning and business intelligence.
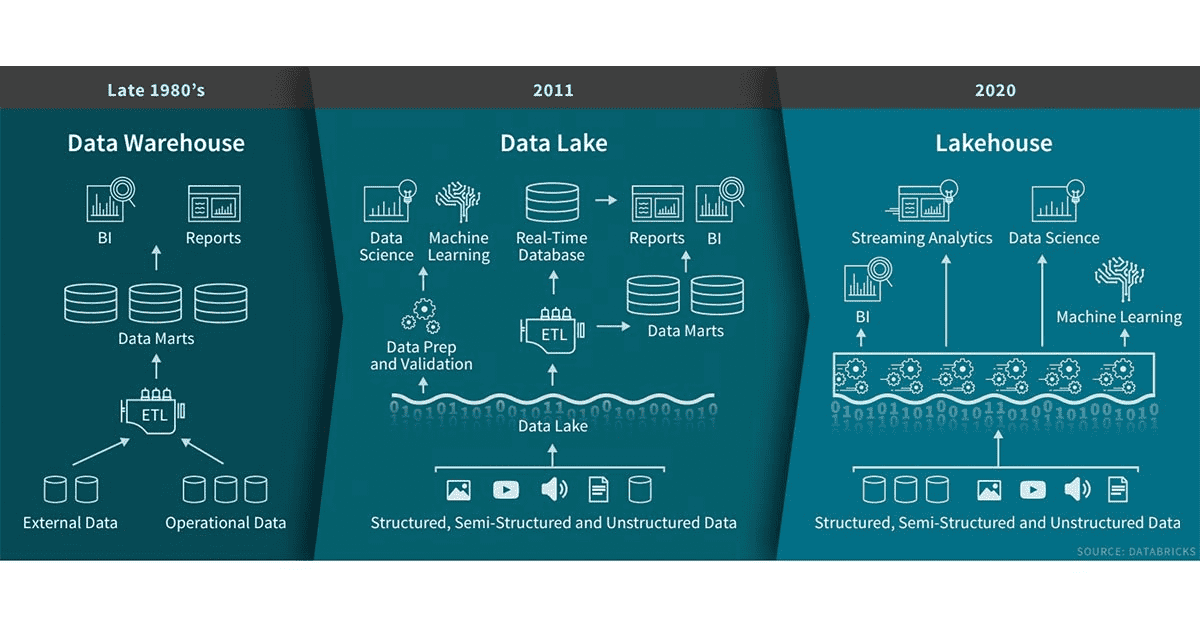
Source: Databricks
All three of these trends will be crucial for enterprises to scale data infrastructure in 2021. They’re useful for companies that were built around data as well as for those that are struggling to sustainably integrate data in their workflows. Find out more about the challenges large companies face to operationalize their data and become data-driven.

blog
What Mature Data Infrastructure Looks Like

Kenneth Leung
6 min


blog
14 Essential Data Engineering Tools to Use in 2024

Abid Ali Awan
10 min

blog
An Introduction to Data Orchestration: Process and Benefits

Srujana Maddula
9 min
blog
Data Lakes vs. Data Warehouses
DataCamp Team
4 min

blog
How to Build Adaptive Data Pipelines for Future-Proof Analytics
Sanjana Putchala
10 min
blog
Cloud Computing and Architecture for Data Scientists

Alex Castrounis
13 min