
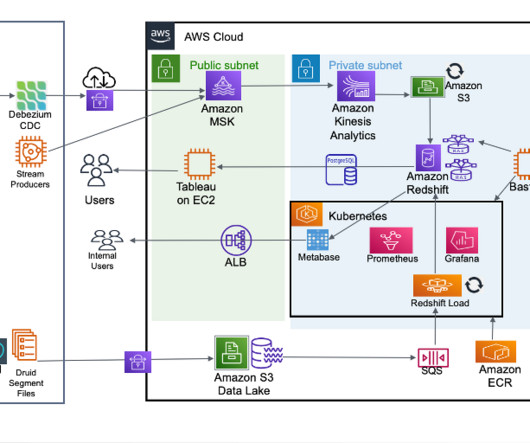
How Gupshup built their multi-tenant messaging analytics platform on Amazon Redshift
AWS Big Data
FEBRUARY 12, 2024
Moreover, no separate effort is required to process historical data versus live streaming data. E.g., use the snapshot-restore feature to quickly create a green experimental cluster from an existing blue serving cluster. Apart from incremental analytics, Redshift simplifies a lot of operational aspects.















Let's personalize your content