
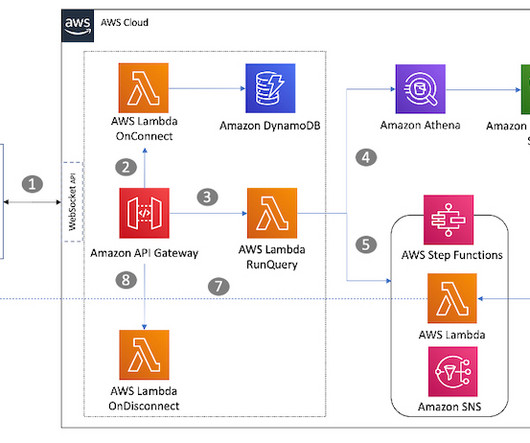
Access Amazon Athena in your applications using the WebSocket API
AWS Big Data
MARCH 2, 2023
Many organizations are building data lakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.










Let's personalize your content