
Implement data warehousing solution using dbt on Amazon Redshift
AWS Big Data
NOVEMBER 17, 2023
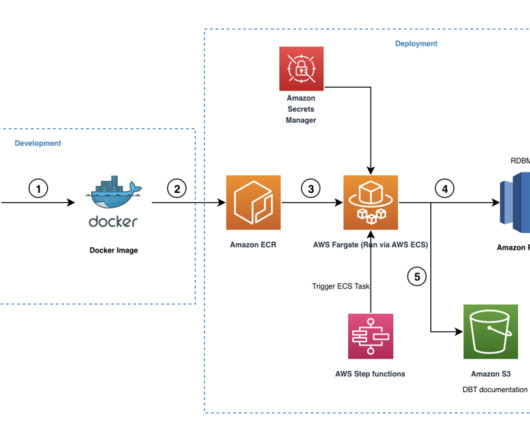
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. For more information, refer SQL models. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. For more information, refer to Redshift set up.























Let's personalize your content