

How GamesKraft uses Amazon Redshift data sharing to support growing analytics workloads
AWS Big Data
NOVEMBER 13, 2023
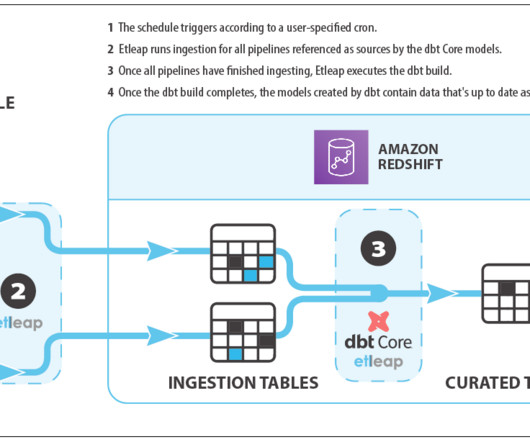
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.














Let's personalize your content