
A Summary Of Gartner’s Recent Innovation Insight Into Data Observability
DataKitchen
AUGUST 8, 2023
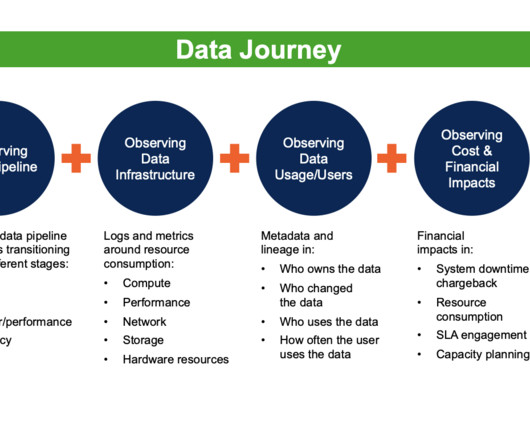
Data Observability leverages five critical technologies to create a data awareness AI engine: data profiling, active metadata analysis, machine learning, data monitoring, and data lineage. Like an apartment blueprint, Data lineage provides a written document that is only marginally useful during a crisis.


















Let's personalize your content