
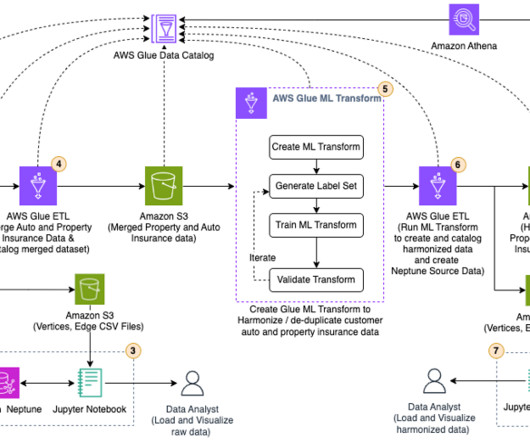
Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
AWS Big Data
JUNE 26, 2023
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive valuable insights from the data. This will open the ML transforms page.











Let's personalize your content