
Amazon OpenSearch Service Under the Hood : OpenSearch Optimized Instances(OR1)
AWS Big Data
APRIL 17, 2024
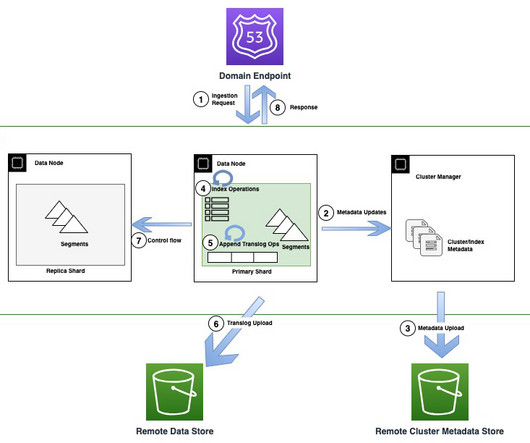
With this new instance family, OpenSearch Service uses OpenSearch innovation and AWS technologies to reimagine how data is indexed and stored in the cloud. Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics.












Let's personalize your content