
Amazon OpenSearch Service Under the Hood : OpenSearch Optimized Instances(OR1)
AWS Big Data
APRIL 17, 2024
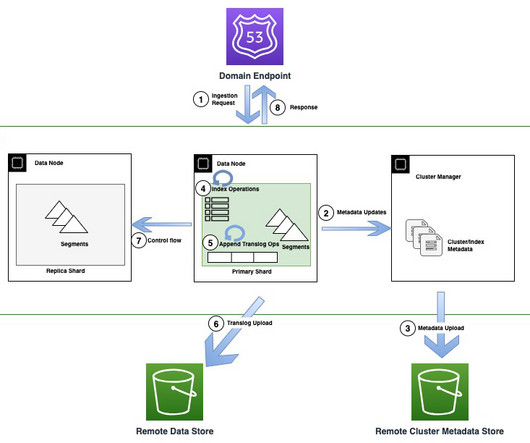
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.





























Let's personalize your content