

Unlocking the Power of Better Data Science Workflows
Smart Data Collective
MARCH 13, 2020
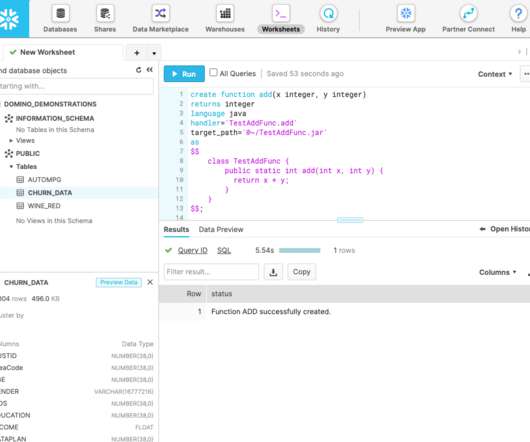
It doesn’t matter what the project or desired outcome is, better data science workflows produce superior results. 5 Tips for Better Data Science Workflows. Data science is a complex field that requires experience, skill, patience, and systematic decision-making in order to be successful. Adding it All Up.















Let's personalize your content