

Moving Enterprise Data From Anywhere to Any System Made Easy
Cloudera
JUNE 2, 2022
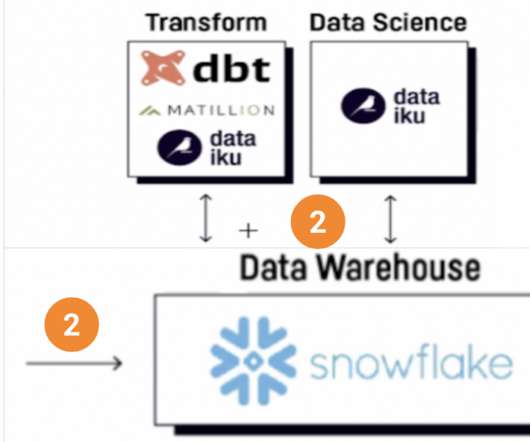
This blog aims to answer two questions: What is a universal data distribution service? Why does every organization need it when using a modern data stack? In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.













Let's personalize your content