
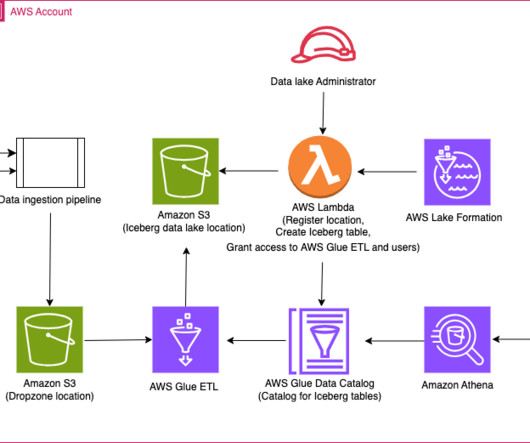
Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
AWS Big Data
MARCH 4, 2024
Apache Iceberg manages these schema changes in a backward-compatible way through its innovative metadata table evolution architecture. For instance, an ecommerce marketplace may initially partition order data by day. Lake Formation helps you centrally manage, secure, and globally share data for analytics and machine learning.











Let's personalize your content