
Speed up queries with the cost-based optimizer in Amazon Athena
AWS Big Data
NOVEMBER 17, 2023
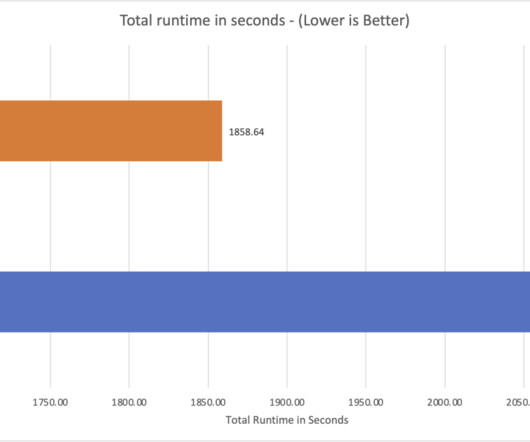
In our testing, the dataset was stored in Amazon S3 in non-compressed Parquet format and the AWS Glue Data Catalog was used to store metadata for databases and tables. Testing on the TPC-DS benchmark showed an 11% improvement in overall query performance when using CBO compared to without it. Pathik Shah is a Sr.













Let's personalize your content