
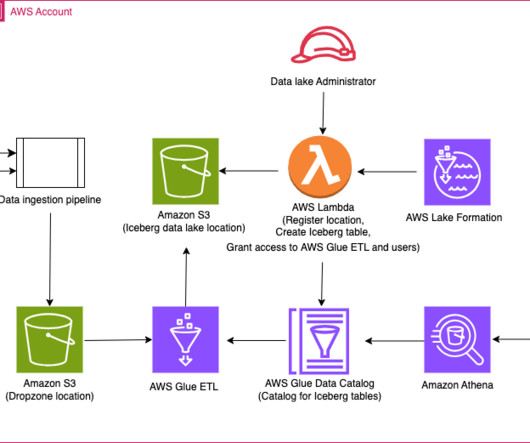
Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
AWS Big Data
MARCH 4, 2024
Provide information for the following parameters: DatalakeUserName DatalakeUserPassword DatabaseName TableName DatabaseLFTagKey DatabaseLFTagValue TableLFTagKey TableLFTagValue Choose Next. Data location permissions work in addition to Lake Formation data permissions to secure information in your data lake. Choose Next.











Let's personalize your content