
Data Discussion Lessons from Brad Pitt
Juice Analytics
APRIL 7, 2021
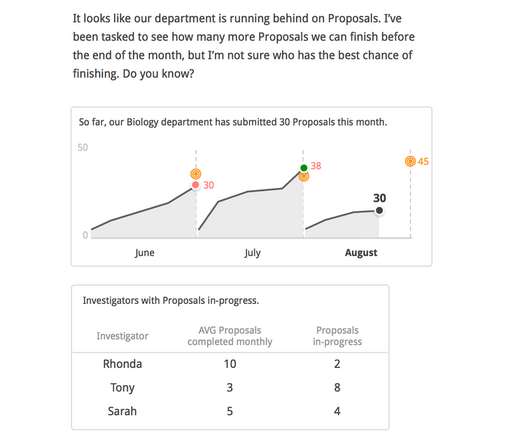
From: Ocean's Eleven (2001) Now imagine yourself giving a pep talk to the next email, PowerPoint slide, or dashboard that you are about to send out. Messages must be clear and focused and eliminate the unnatural, mechanical chart headings and the unnecessarily complex statistical jargon. How exactly is this metric calculated?













Let's personalize your content