
Measuring Validity and Reliability of Human Ratings
The Unofficial Google Data Science Blog
JULY 18, 2023
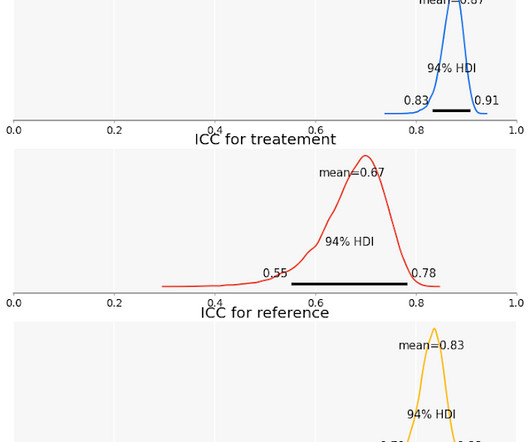
If they roll two dice and apply a label if the dice rolls sum to 12 they will agree 85% of the time, purely by chance. We normally have lots of labelers and items in our dataset, and priors give a form of regularization that better handles cases where data might be sparse and makes the model less prone to overfitting.








Let's personalize your content