
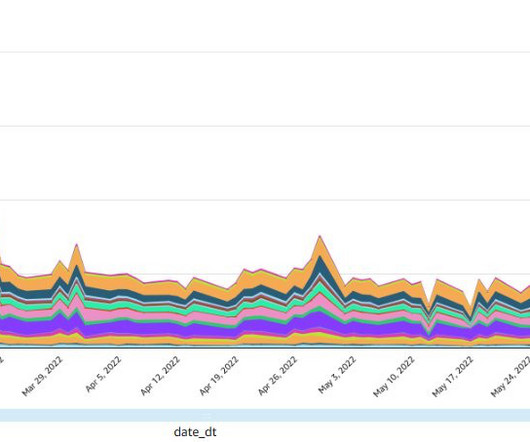
Combine transactional, streaming, and third-party data on Amazon Redshift for financial services
AWS Big Data
FEBRUARY 1, 2024
The following are some of the key business use cases that highlight this need: Trade reporting – Since the global financial crisis of 2007–2008, regulators have increased their demands and scrutiny on regulatory reporting. FactSet has several datasets available in the AWS Data Exchange marketplace, which we used for reference data.











Let's personalize your content