
Automating Model Risk Compliance: Model Validation
DataRobot Blog
MAY 26, 2022
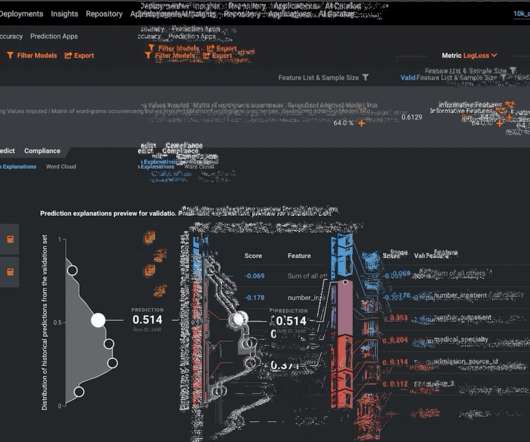
When the FRB’s guidance was first introduced in 2011, modelers often employed traditional regression -based models for their business needs. In addition to the model metrics discussed above for classification, DataRobot similarly provides fit metrics for regression models, and helps the modeler visualize the spread of model errors.












Let's personalize your content