

How Amazon Devices scaled and optimized real-time demand and supply forecasts using serverless analytics
AWS Big Data
FEBRUARY 1, 2023
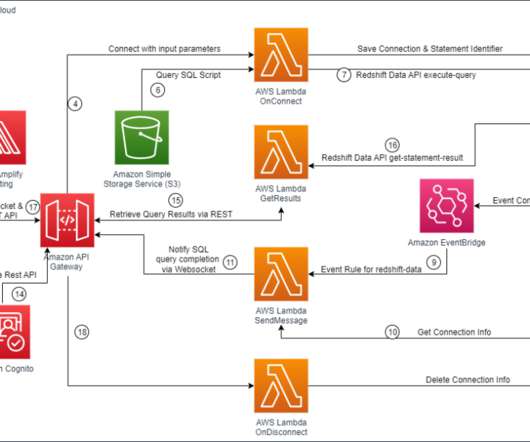
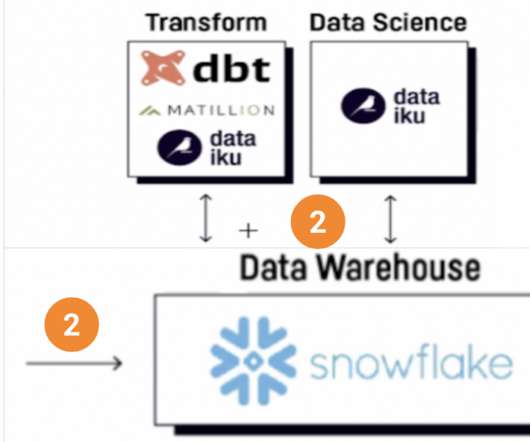
This data is used in procuring devices’ inventory to meet Amazon customers’ demands. With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data.

















Let's personalize your content