

Migrate an existing data lake to a transactional data lake using Apache Iceberg
AWS Big Data
OCTOBER 3, 2023
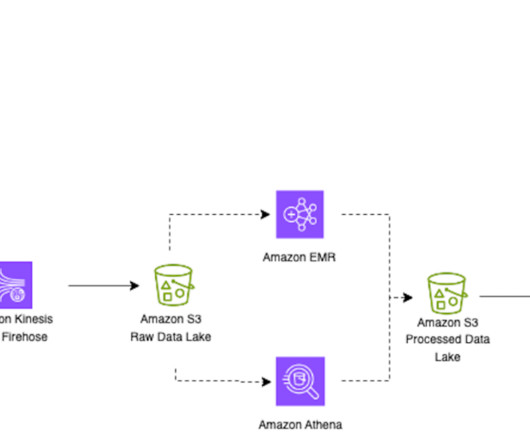
You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Analytics use cases on data lakes are always evolving. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.















Let's personalize your content