
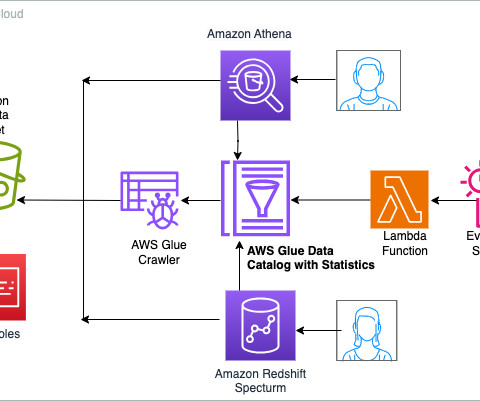
Enhance query performance using AWS Glue Data Catalog column-level statistics
AWS Big Data
NOVEMBER 22, 2023
Data lakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.














Let's personalize your content