
Implement data warehousing solution using dbt on Amazon Redshift
AWS Big Data
NOVEMBER 17, 2023
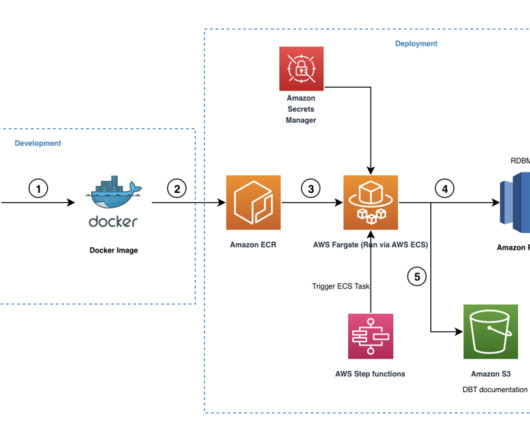
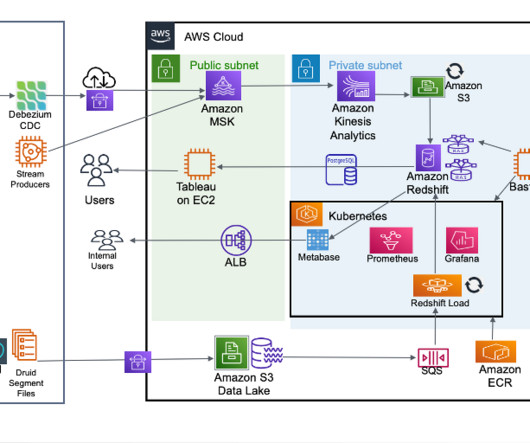
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. This mechanism allows developers to focus on preparing the SQL files per the business logic, and the rest is taken care of by dbt.



























Let's personalize your content