

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
AWS Big Data
APRIL 3, 2024
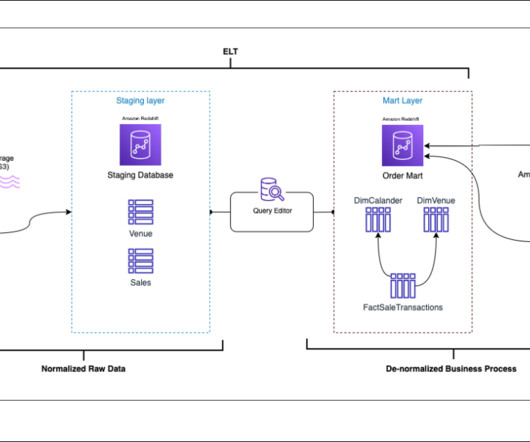
Manage your Iceberg table with AWS Glue You can use AWS Glue to ingest, catalog, transform, and manage the data on Amazon Simple Storage Service (Amazon S3). With AWS Glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog.


















Let's personalize your content