

Synthetic data generation: Building trust by ensuring privacy and quality
IBM Big Data Hub
NOVEMBER 29, 2023
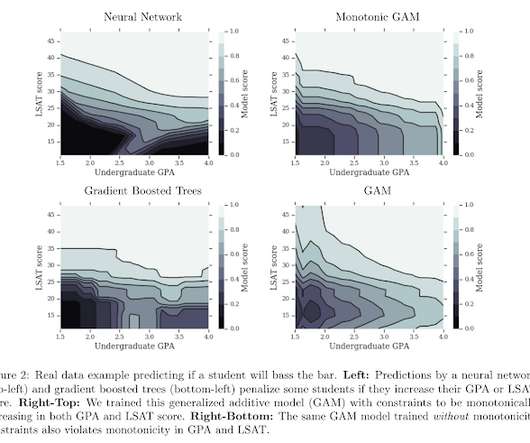
Furthermore, as modeling techniques become increasingly sophisticated in data science, including deep learning and predictive and generative models, companies and vendors must work diligently to prevent unintentional connections that could leak a person’s identity and expose them to third-party attacks.























Let's personalize your content