
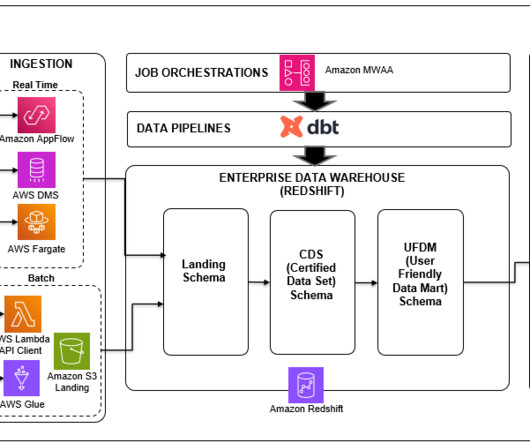
Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
AWS Big Data
NOVEMBER 9, 2023
In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.











Let's personalize your content