

Data governance in the age of generative AI
AWS Big Data
FEBRUARY 29, 2024
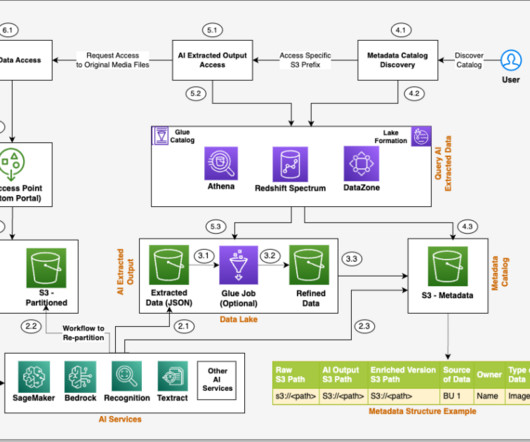
Data governance is a critical building block across all these approaches, and we see two emerging areas of focus. First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from data warehouses.
















Let's personalize your content