

Exploring real-time streaming for generative AI Applications
AWS Big Data
MARCH 25, 2024
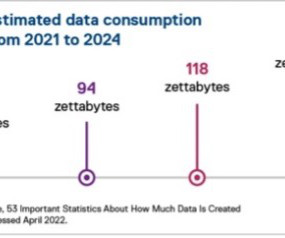
Streaming data facilitates the constant flow of diverse and up-to-date information, enhancing the models’ ability to adapt and generate more accurate, contextually relevant outputs. With a file system sink connector, Apache Flink jobs can deliver data to Amazon S3 in open format (such as JSON, Avro, Parquet, and more) files as data objects.











Let's personalize your content