

How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
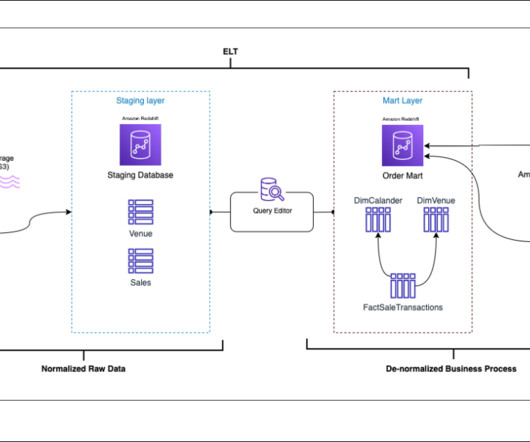
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. For example, for certain queries, Athena runtime was 2x–4x faster than Snowflake.













Let's personalize your content