

Migrate an existing data lake to a transactional data lake using Apache Iceberg
AWS Big Data
OCTOBER 3, 2023
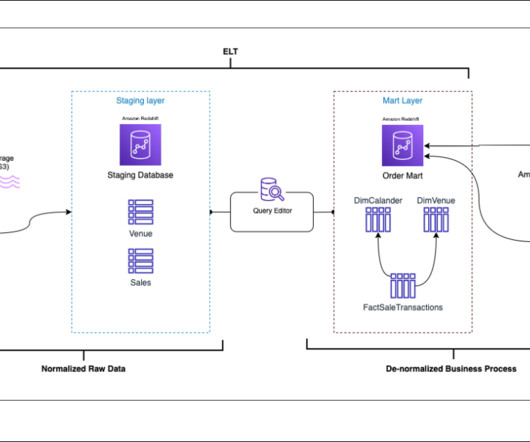
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.












Let's personalize your content