
Introducing AWS Glue crawler and create table support for Apache Iceberg format
AWS Big Data
AUGUST 16, 2023
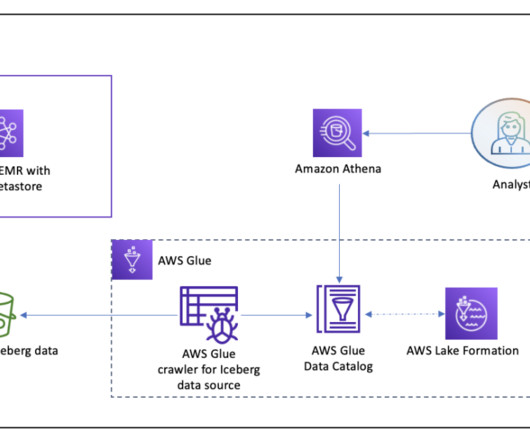
Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. With each crawler run, the crawler inspects each of the S3 paths and catalogs the schema information, such as new tables, deletes, and updates to schemas in the Data Catalog.





















Let's personalize your content