
Apache Iceberg optimization: Solving the small files problem in Amazon EMR
AWS Big Data
OCTOBER 3, 2023
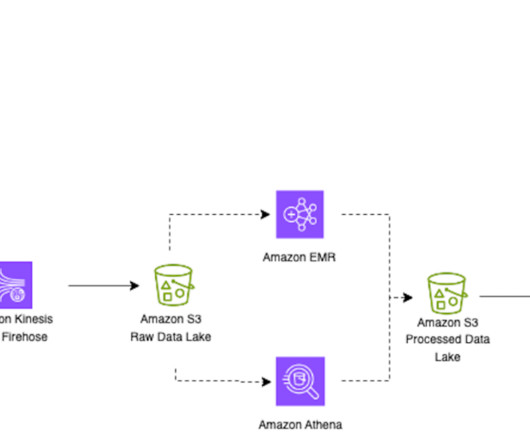
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) data lake that is using the Apache Iceberg open table format and running on the Amazon EMR big data platform.


























Let's personalize your content