
Migrate your existing SQL-based ETL workload to an AWS serverless ETL infrastructure using AWS Glue
AWS Big Data
JULY 31, 2023
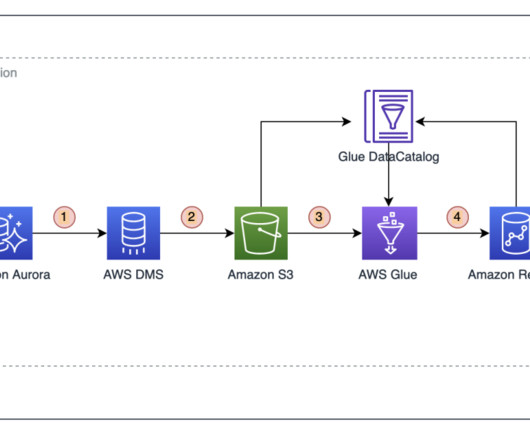
Customers often use many SQL scripts to select and transform the data in relational databases hosted either in an on-premises environment or on AWS and use custom workflows to manage their ETL. AWS Glue is a serverless data integration and ETL service with the ability to scale on demand.















Let's personalize your content