

Streaming Ingestion for Apache Iceberg With Cloudera Stream Processing
Cloudera
MARCH 2, 2023
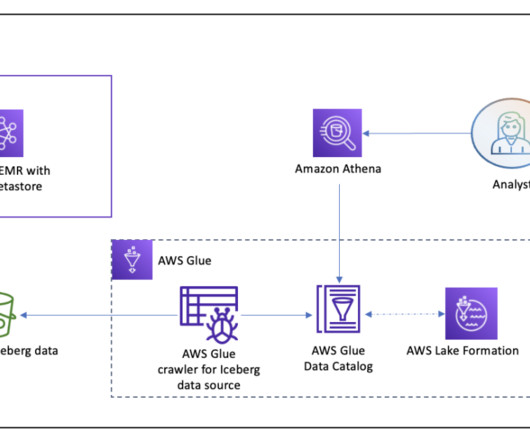
The CM Host field is only available in the CDP Public Cloud version of SSB because the streaming analytics cluster templates do not include Hive, so in order to work with Hive we will need another cluster in the same environment, which uses a template that has the Hive component.


















Let's personalize your content