

How smava makes loans transparent and affordable using Amazon Redshift Serverless
AWS Big Data
DECEMBER 21, 2023
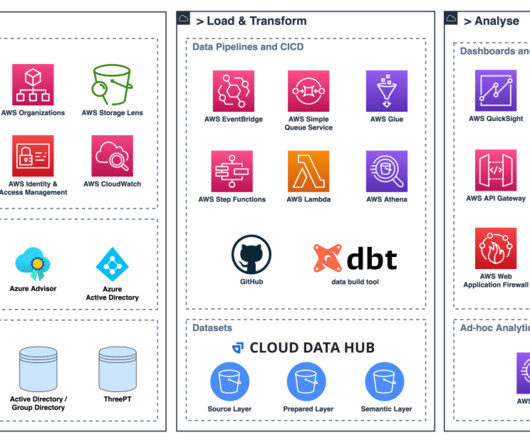
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud data warehouse.











Let's personalize your content