
BMW Cloud Efficiency Analytics powered by Amazon QuickSight and Amazon Athena
AWS Big Data
NOVEMBER 15, 2023
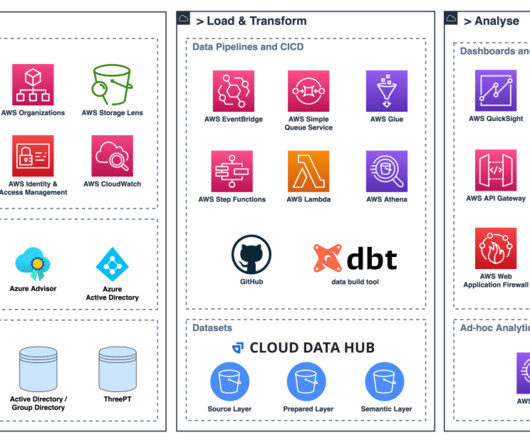
It seamlessly consolidates data from various data sources within AWS, including AWS Cost Explorer (and forecasting with Cost Explorer ), AWS Trusted Advisor , and AWS Compute Optimizer. Data providers and consumers are the two fundamental users of a CDH dataset.












Let's personalize your content