
Speed up queries with the cost-based optimizer in Amazon Athena
AWS Big Data
NOVEMBER 17, 2023
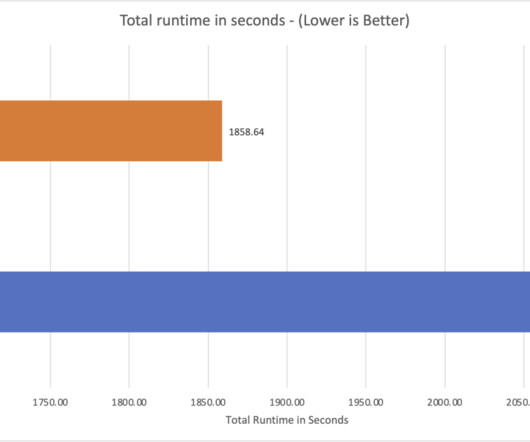
Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata. By using these statistics, CBO improves query run plans and boosts the performance of queries run in Athena.
















Let's personalize your content