
Measuring Validity and Reliability of Human Ratings
The Unofficial Google Data Science Blog
JULY 18, 2023
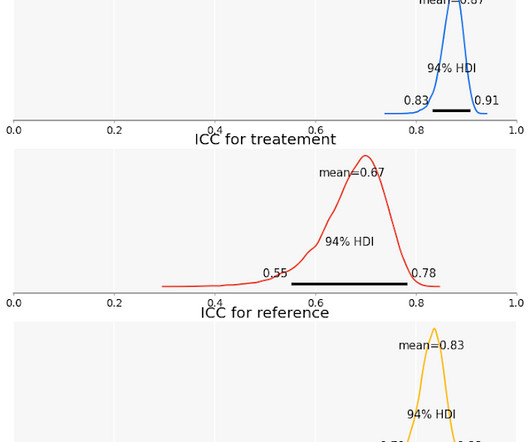
If they roll two dice and apply a label if the dice rolls sum to 12 they will agree 85% of the time, purely by chance. In practice, we see that the ICC computed this way is almost always equal to the version derived exclusively from the relevant slice of the data, regardless of the value of $rho$.








Let's personalize your content