
Can Machine Learning Address Risk Parity Concerns?
Smart Data Collective
FEBRUARY 28, 2023
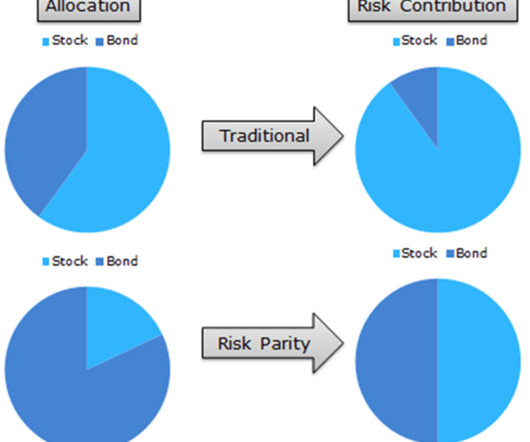
Here at Smart Data Collective, we have blogged extensively about the changes brought on by AI technology. One of the most important changes pertains to risk parity management. We are going to provide some insights on the benefits of using machine learning for risk parity analysis. What is risk parity?












Let's personalize your content