
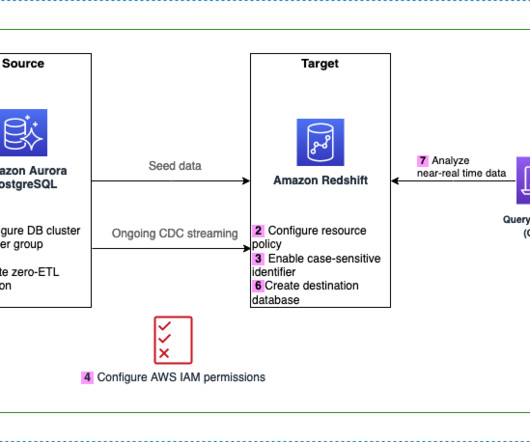
Achieve near real time operational analytics using Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift
AWS Big Data
APRIL 10, 2024
“Data is at the center of every application, process, and business decision. Customers across industries are becoming more data driven and looking to increase revenue, reduce cost, and optimize their business operations by implementing near real time analytics on transactional data, thereby enhancing agility.
























Let's personalize your content