
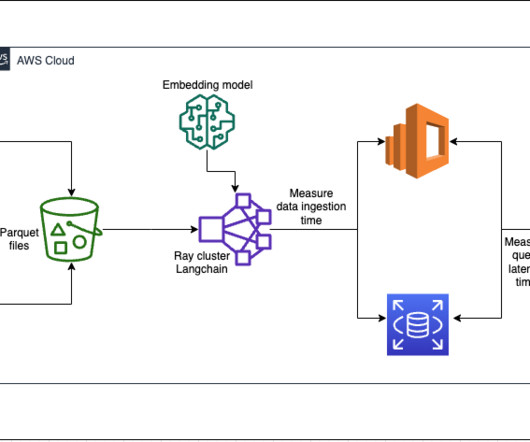
Build a RAG data ingestion pipeline for large-scale ML workloads
AWS Big Data
MARCH 13, 2024
You need to use the user name and password for cloning the OSCAR data: GIT_LFS_SKIP_SMUDGE=1 git clone [link] cd OSCAR-2301 git lfs pull --include en_meta cd en_meta for F in `ls *.zst`; After you review the cluster configuration, select the jump host as the target for the run command. zst`; do zstd -d $F; done rm *.zst













Let's personalize your content