

Optimize data layout by bucketing with Amazon Athena and AWS Glue to accelerate downstream queries
AWS Big Data
APRIL 25, 2024
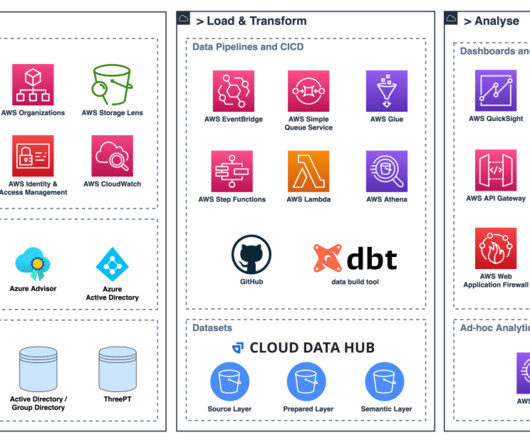
By partitioning data, downstream analytical queries can skip irrelevant partitions, reducing the amount of data that needs to be scanned and processed. Alternatively, you can use AWS Glue for Apache Spark, which provides built-in support for bucketing configurations during the data transformation process.
















Let's personalize your content